publications
publications by categories in reversed chronological order.
2025
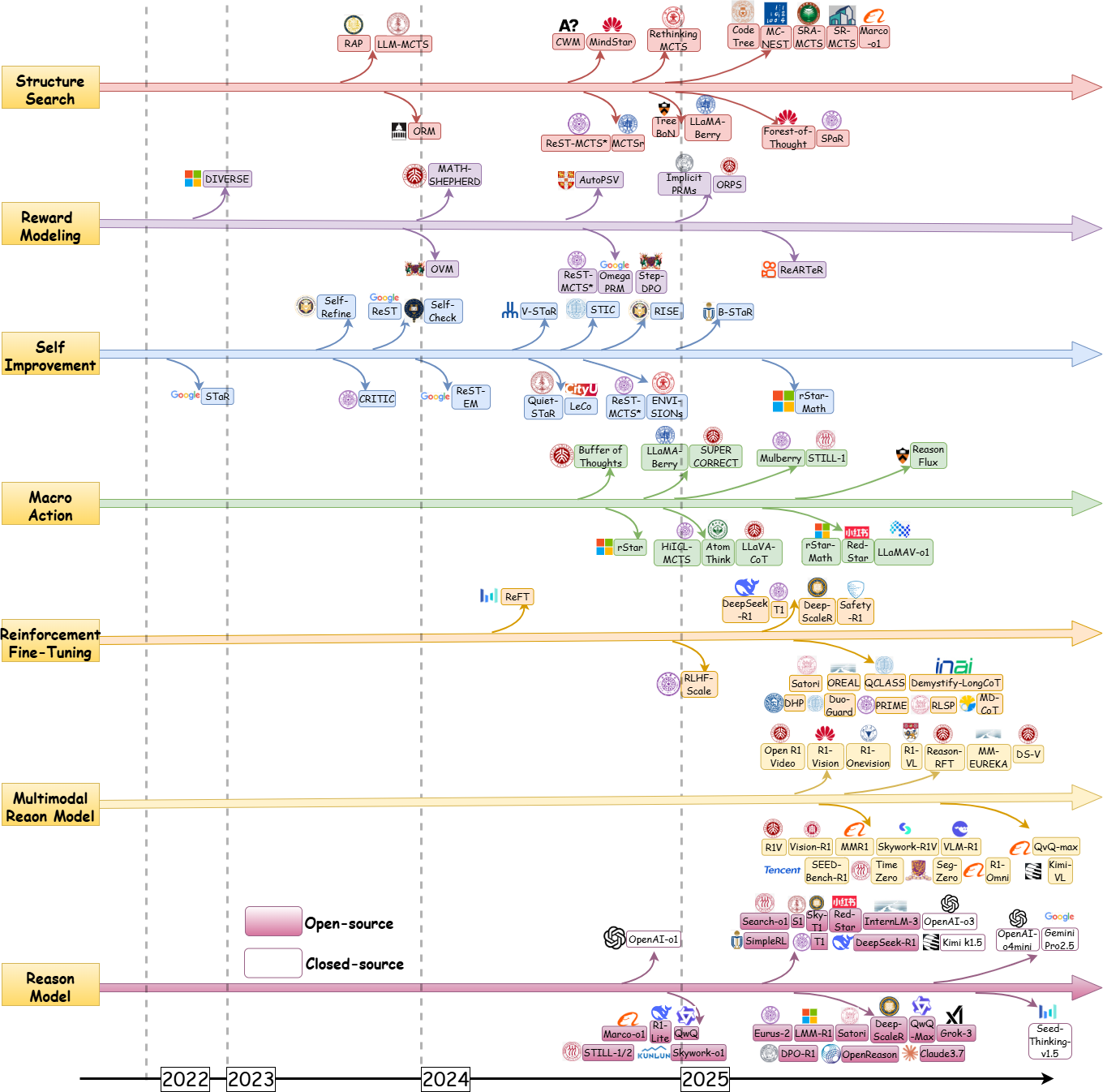
- From System 1 to System 2: A Survey of Reasoning Large Language ModelsZhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhiwei Li, Bao-Long Bi, Ling-Rui Mei, Junfeng Fang, Zhijiang Guo, Le Song, and Cheng-Lin LiuTPAMI, 2025
Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI’s o1/o3 and DeepSeek’s R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time GitHub Repository to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
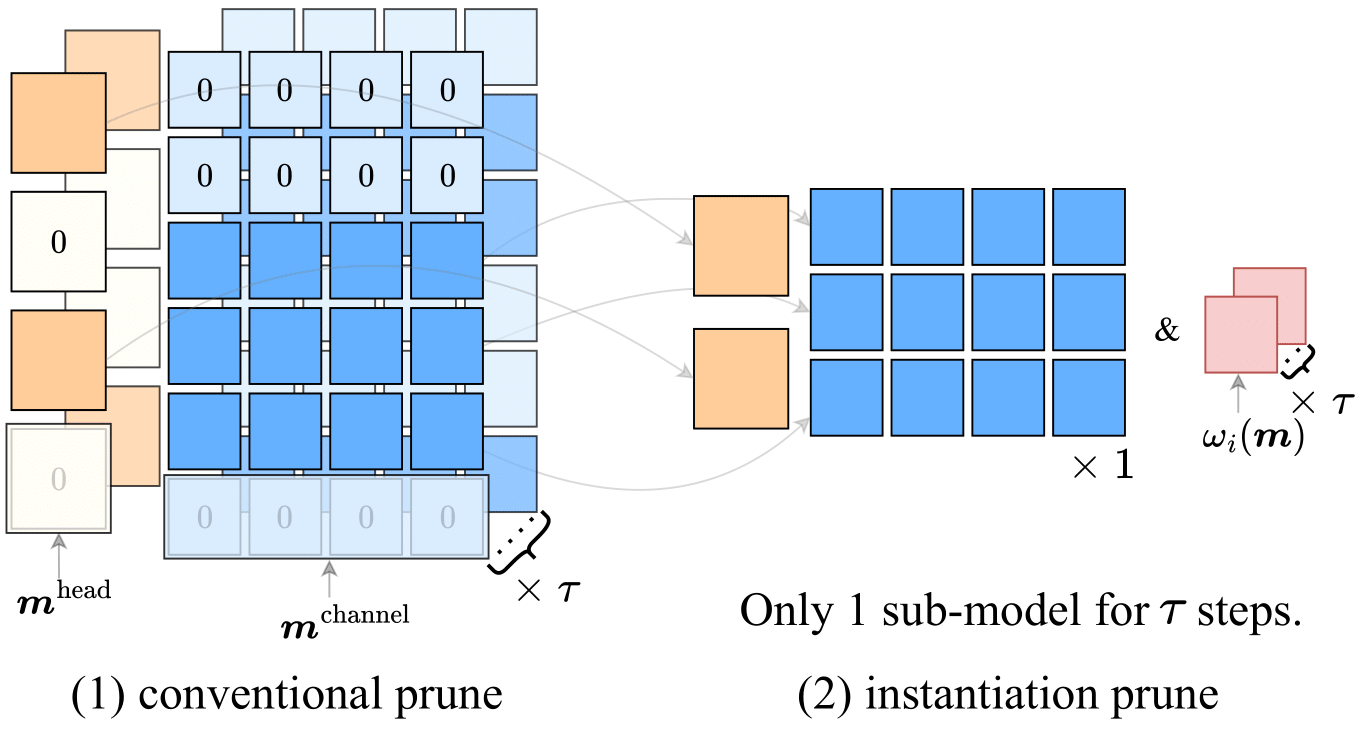
- Computation and Memory-Efficient Model Compression with Gradient ReweightingZhiwei Li*, Yuesen Liao*, Binrui Wu, Yuquan Zhou, Xupeng Shi, Dongsheng Jiang, Yin Li, and Weizhong ZhangNeurIPS, 2025
Pruning is a commonly employed technique for deep neural networks (DNNs) aiming at compressing the model size to reduce computational and memory costs during inference. In contrast to conventional neural networks, large language models (LLMs) pose a unique challenge regarding pruning efficiency due to their substantial computational and memory demands. Existing methods, particularly optimization-based ones, often require considerable computational resources in gradient estimation because they cannot effectively leverage weight sparsity of the intermediate pruned network to lower compuation and memory costs in each iteration. The fundamental challenge lies in the need to frequently instantiate intermediate pruned sub-models to achieve these savings, a task that becomes infeasible even for moderately sized neural networks. To this end, this paper proposes a novel pruning method for DNNs that is both computationally and memory-efficient. Our key idea is to develop an effective reweighting mechanism that enables us to estimate the gradient of the pruned network in current iteration via reweigting the gradient estimated on an outdated intermediate sub-model instantiated at an earlier stage, thereby significantly reducing model instantiation frequency. We further develop a series of techniques, e.g., clipping and preconditioning matrix, to reduce the variance of gradient estimation and stabilize the optimization process. We conducted extensive experimental validation across various domains. Our approach achieves 50% sparsity and a 1.58x speedup in forward pass on Llama2-7B model with only 6 GB of memory usage, outperforming state-of-the-art methods with respect to both perplexity and zero-shot performance. As a by-product, our method is highly suited for distributed sparse training and can achieve a 2x speedup over the dense distributed baselines.
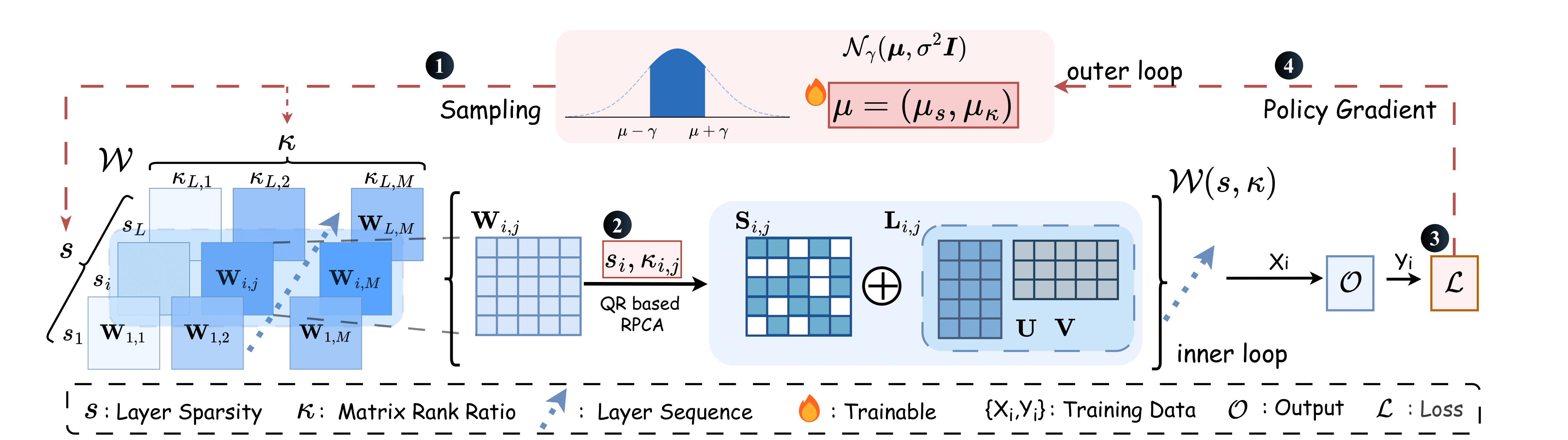
- Compress Large Language Models via Collaboration Between Learning and Matrix ApproximationYuesen Liao*, Zhiwei Li*, Binrui Wu, Zihao Cheng, Su Zhao, Shuai Chen, and Weizhong ZhangNeurIPS, 2025
Sparse and low-rank matrix composite approximation has emerged as a promising paradigm for compressing large language models (LLMs), offering a more flexible pruning structure than conventional methods based solely on sparse matrices. The significant variation in weight redundancy across layers, along with the differing rank and sparsity structures of weight matrices, makes identifying the globally optimal pruning structure extremely challenging. Existing methods often depend on uniform or manually designed heuristic rules to allocate weight sparsity across layers, subsequently compressing each matrix using matrix approximation techniques. Given the above theoretical difficulty in global compression of LLMs and the limited computational and data resources available compared to the training phase, we argue that a collaboration between learning and matrix approximation is essential for effective compression. In this paper, we propose a novel LLM compression framework based on generalized bilevel optimization that naturally formulates an effective collaborative mechanism. Specifically, the outer loop frames the weight allocation task as a probabilistic optimization problem, enabling the automatic learning of both layer-wise sparsities and matrix-wise retained ranks, while the inner loop solves the corresponding sparsity and rank-constrained model compression problem via matrix approximation. Our main technical contributions include two key innovations for efficiently solving this bilevel optimization problem. First, we introduce a truncated Gaussian prior-based probabilistic parameterization integrated with a policy gradient estimator, which avoids expensive backpropagation and stabilizes the optimization process. Second, we design an adapted QR-based matrix approximation algorithm that significantly accelerates inner loop computations. Extensive experiments on Phi-3 and the LLama-2/3 family demonstrate the effectiveness of our method. Notably, it maintains over 95% zero-shot accuracy under 50% sparsity and achieves up to 2× inference speedup.
- Efficient Representativeness-Aware Coreset SelectionZihao Cheng, Binrui Wu, Zhiwei Li, Yuesen Liao, Su Zhao, Shuai Chen, Yuan Gao, and Weizhong ZhangNeurIPS, 2025
Dynamic coreset selection is a promising approach for improving the training efficiency of deep neural networks by periodically selecting a small subset of the most representative or informative samples, thereby avoiding the need to train on the entire dataset. However, it remains inherently challenging due not only to the complex interdependencies among samples and the evolving nature of model training, but also to a critical coreset representativeness degradation issue identified and explored in-depth in this paper, that is, the representativeness or information content of the coreset degrades over time as training progresses. Therefore, we argue that, in addition to designing accurate selection rules, it is equally important to endow the algorithms with the ability to assess the quality of the current coreset. Such awareness enables timely re-selection, mitigating the risk of overfitting to stale subsets—a limitation often overlooked by existing methods. To this end, this paper proposes an Efficient Representativeness-Aware Coreset Selection method for deep neural networks, a lightweight framework that enables dynamic tracking and maintenance of coreset quality during training. While the ideal criterion—gradient discrepancy between the coreset and the full dataset—is computationally prohibitive, we introduce a scalable surrogate based on the signal-to-noise ratio (SNR) of gradients within the coreset, which is the main technical contribution of this paper and is also supported by our theoretical analysis. Intuitively, a decline in SNR indicates overfitting to the subset and declining representativeness. Leveraging this observation, our method triggers coreset updates without requiring costly Hessian or full-batch gradient computations, maintaining minimal computational overhead. Experiments on multiple datasets confirm the effectiveness of our approach. Notably, compared with existing gradient-based dynamic coreset selection baselines, our method achieves up to a 5.4% improvement in test accuracy across multiple datasets.
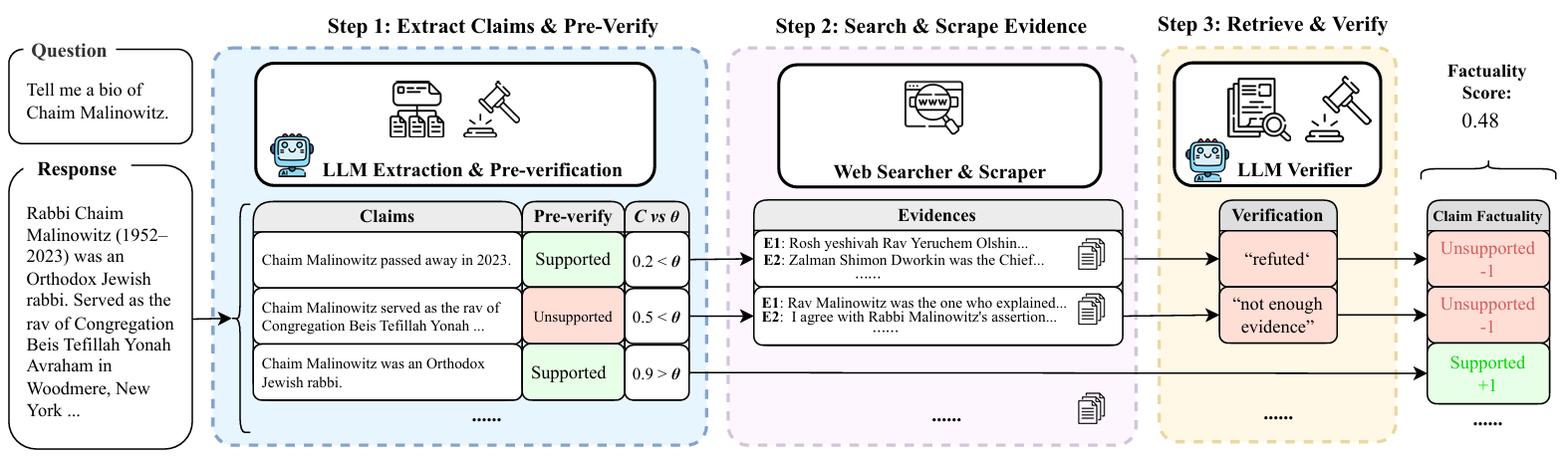
- FaStFact: Faster, Stronger Long-Form Factuality Evaluations in LLMsYingjia Wan, Haochen Tan, Xiao Zhu, Xinyu Zhou, Zhiwei Li, Qingsong Lv, Changxuan Sun, Jiaqi Zeng, Yi Xu, Jianqiao Lu, Yinhong Liu, and Zhijiang GuoEMNLP Findings, 2025
Evaluating the factuality of long-form generations from Large Language Models (LLMs) remains challenging due to accuracy issues and costly human assessment. Prior evaluation pipelines attempt this by decomposing text into claims, searching for evidence, and verifying claims, but suffer from critical drawbacks: (1) inefficiency due to complex pipeline components unsuitable for long LLM outputs, and (2) ineffectiveness stemming from inaccurate claim sets and insufficient evidence collection of one-line SERP snippets. To address these limitations, we adapt the existing decompose-then-verify evaluation framework and propose FaStFact, a fast and strong evaluation pipeline that achieves the highest alignment with human evaluation and efficiency among existing baselines. FaStFact first employs chunk-level claim extraction integrated with confidence-based pre-verification, significantly reducing the cost of web searching and inference calling while ensuring reliability. For searching and verification, it gathers document-level evidence from crawled website pages for retrieval during verification, addressing the evidence insufficiency problem in previous pipelines. Extensive experiments based on an aggregated and manually annotated benchmark demonstrate the reliability of FaStFact in both efficiently and effectively evaluating the factuality of long-form LLM generations. We submit the paper with code and benchmark, and will make them publicly available to facilitate research.

2024
- Low Precision Local Training is Enough for Federated LearningZhiwei Li*, Yiqiu Li*, Binbin Lin, Zhongming Jin, and Weizhong ZhangNeurIPS, 2024
Federated Learning (FL) is a prevalent machine learning paradigm designed to address challenges posed by heterogeneous client data while preserving data privacy. Unlike distributed training, it typically orchestrates resource-constrained edge devices to communicate via a low-bandwidth communication network with a central server. This urges the development of more computation and communication efficient training algorithms. In this paper, we propose an efficient FL paradigm, where the local models in the clients are trained with low-precision operations and communicated with the server in low precision format, while only the model aggregation in the server is performed with high-precision computation. We surprisingly find that high precision models can be recovered from the low precision local models with proper aggregation in the server. In this way, both the workload in the client-side and the communication cost can be significantly reduced. We theoretically show that our proposed paradigm can converge to the optimal solution as the training goes on, which demonstrates that low precision local training is enough for FL. Our paradigm can be integrated with existing FL algorithms flexibly. Experiments across extensive benchmarks are conducted to showcase the effectiveness of our proposed method. Notably, the models trained by our method with the precision as low as 8 bits are comparable to those from the full precision training. As a by-product, we show that low precision local training can relieve the over-fitting issue in local training, which under heterogeneous client data can cause the client models drift further away from each other and lead to the failure in model aggregation. Code is released at https://github.com/digbangbang/LPT-FL.
